
Kento
Add one line of code, Cut your AI bill by 40%
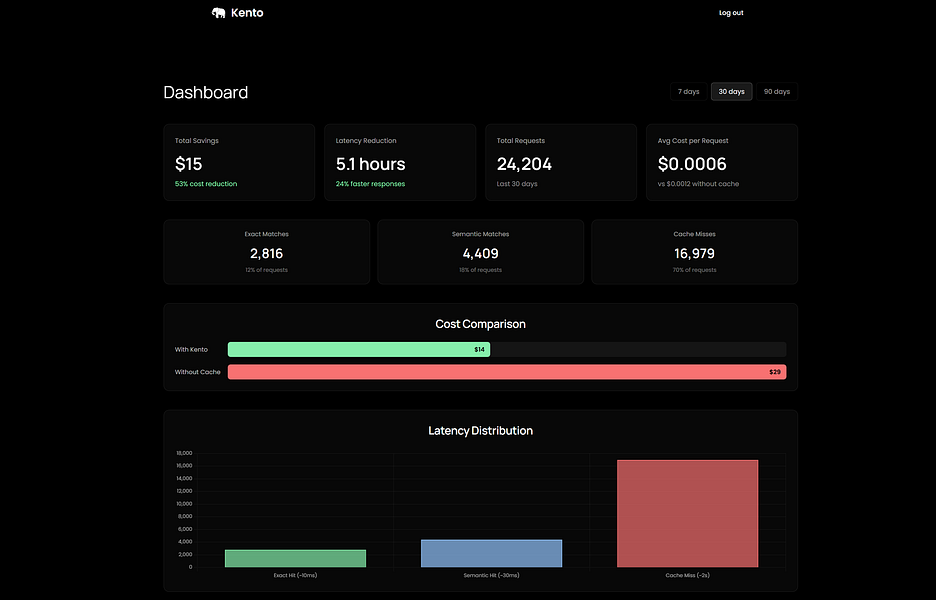
Kento cuts your LLM API costs by 30-70% through semantic caching. Instead of sending similar requests to ChatGPT every time, Kento recognizes when a new query is semantically similar to one you've or someone else already made and returns the cached response instantly. You add one line of code to your existing setup and it works with all major LLM providers.







